Hadoop是一个海量数据分布式的存储和计算框架
三大核心设计有HDFS分布式存储系统、MapReduce分布式计算框架、Yarn分布式资源管理系统
一、HDFS分布式存储系统①HDFS是主从式结构,包括一个主节点NameNode和多个从节点DataNodeNameNode是管理节点,主要存储元数据信息,包括命…
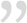
Hadoop是一个海量数据分布式的存储和计算框架
三大核心设计有HDFS分布式存储系统、MapReduce分布式计算框架、Yarn分布式资源管理系统
一、HDFS分布式存储系统<特点:存储量大、容错性>
①HDFS是主从式结构,包括一个主节点NameNode和多个从节点DataNode
NameNode是管理节点,主要存储元数据信息,包括命名空间信息、块信息等
DataNode是工作节点,主要是存储数据,每个数据块默认3个副本,分布在两个机架的3个节点上,DataNode会定期<默认3秒>向NameNode发送心跳信息
SecondaryNameNode是检查点节点,NameNode的冷备<当NameNode故障,它不能立即替换,而是存储了NameNode大部分信息,从而减少故障损失>,主要工作是定时去获取NameNode的edit logs并更新到自己的fsimage中,然后将这个fsimage拷贝给NameNode,NameNode下次重启会使用拷贝过来的这个fsimage,从而减少启动时间
※元数据映像文件<fsimage><完整的元数据>、编辑日志<edit logs><对数据的改动>
②HDFS的读写流程
HDFS的读写操作都要经过NN
1、写流程
1.首先Client通过Create()并给NN发送RPC<远程过程调用协议>请求,NN检查目标文件是否存在,然后返回是否可以上传
2.Client对数据切分成block,一个block默认128M,然后向NN请求可以上传的DN,NN返回可以上传的DN
3.Client上传数据到DN,然后第一个DN接收完反馈给Client,后台进行备份
4.第一个block传输完成继续下一个
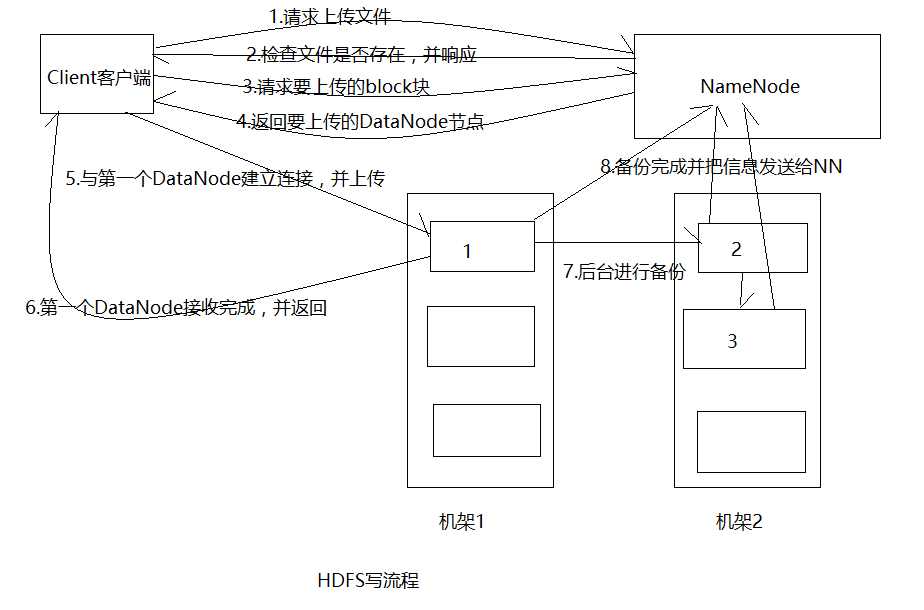
2、读流程
1.Client通过Open()并给NN发送RPC<远程过程调用协议>请求,NN返回DataNode的目标位置
2.Client通过就近原则与DataNode建立流连接,获取数据
3.Client接收完成对文件进行合并
二、MapReduce分布式计算框架
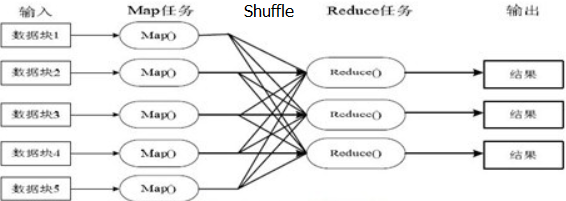
①MapReduce主要分为Map和Reduce,Map和Reduce的输入输出都是<K,V>
Map程序处理的数据是从HDFS中的DataNode的block中加载的,并产生一个临时的结果
Reduce程序把临时的中间结果进行汇总,然后输出到HDFS中
②Shuffle<洗牌>过程:将Map的输出作为Reduce的输入的过程就是Shuffle【内存缓冲区/环形缓冲区】
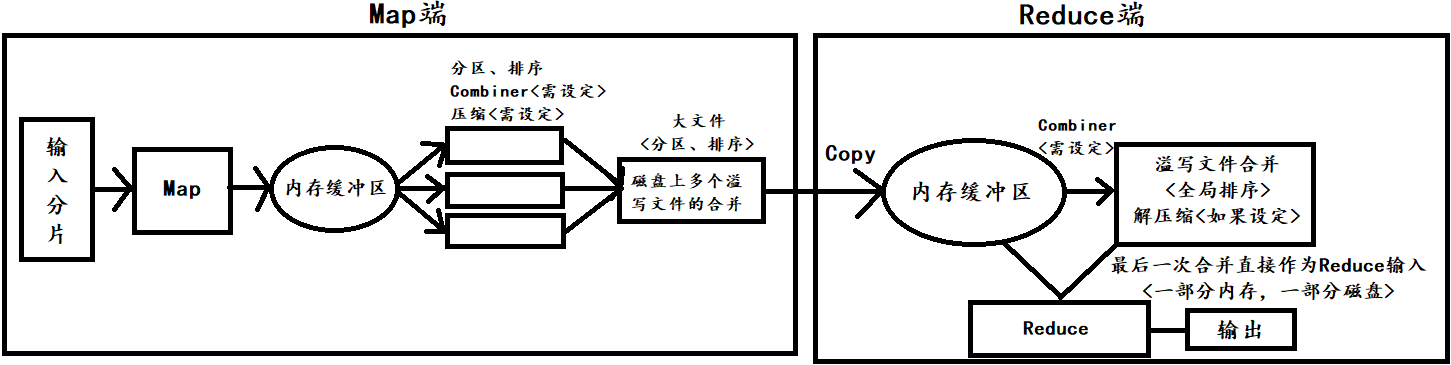
Map程序处理完数据会缓存到内存缓冲区<预排序>,每个Map Task都有一个内存缓冲区,内存缓冲区大小默认是100M,当内存缓冲区内容达到默认阈值<0.8>也就是80M,会锁定这80M启动单独线程溢写,Map Task还可以往剩下的20M内存写,如果内存缓冲区满了,Map会阻塞直到溢写完成,80M溢写到磁盘前先以Key的Hash值对Reduce个数取模进行分区,然后对每个分区的数据按Key进行排序<快速排序算法,二次排序>、聚合Combiner<需要设定>、压缩<需要设定>,最后留在内存缓冲区的数据也会生成1个溢写文件,最终1个Map Task生成多个溢写文件的合并Merge,合并到一个大的分区的、排序的<基于内存全局排序>文件中
Reduce Task会不断通过RPC获取Map Task是否完成,Map Task结束Reduce Task就去Map端复制,复制过来放到内存缓冲区<默认JVM堆的大小>,达到阈值溢写,溢写前会聚合Combiner<需要设定>,溢写过程中后台线程会把这些文件合并<全局排序>、解压缩<如果设置>,当溢写全部完成,最后一次合并成一个排序的文件作为Reduce的输入<最后合并:一部分内存一部分磁盘>
三、Yarn分布式资源管理系统<Hadoop2.0>
Yarn是主从式结构,由主节点RM和从节点NM组成,负责为运算程序提供服务器运行资源,它的出现主要是将资源管理和作业调度分离
主要架构包括:
APPLicationMaster<节点应用管理类>
ResourceManager<资源管理程序>
NodeManager<节点管理器>
Container<资源(CPU、内存)>
Yarn执行流程
第一步:用户向Yarn提交应用程序<AM、启动AM命令、用户程序等>
第二步:RM为该程序分配第一个资源,并与NM通信,要求NM在资源中启动AM
第三步:AM首先向RM注册<通过RM监控应用程序运行状态>,然后通过轮询的方式为内部要执行的任务申请并领取资源 ,一旦得到资源,便与NM通信,以启动对应的任务
第四步:各个任务通过心跳与AM通信,待所有任务运行完成后,AM向RM注销,整个应用程序运行结束,释放资源
扫一扫在手机打开
评论
已有0条评论
0/150
提交
热门评论
相关推荐